2403
Low-Latency Reconstruction for Real-Time Speech MRI1Electrical Engineering, University of Southern California, Los Angeles, CA, United States
Synopsis
Real-time MRI provides the ability to visualize dynamic processes as they occur. This may require low latency, defined as the total time between when a pose occurs and when a digital representation appears on a screen for interpretation and/or use by the scan operator. We explore the tradeoff between image quality and latency for speech production imaging, where high-latency constrained reconstruction is the current state-of-the-art. We demonstrate that image quality adequate for a) confirmation of stimuli compliance and b) identification of subject motion can be provided to the scan operator with a latency less than 70ms.
Introduction
Real time MRI (RT-MRI) involves the continuous acquisition of MR images of a dynamically evolving process, for example the movement of vocal tract articulators during speech production 1,2. Two basic requirements are temporal resolution fast enough to discern the dynamics, and latency low enough to fulfill application-specific needs 3. Here, latency is defined as the total time elapsed between a motion state occurring and its on-screen representation. The latency requirements are dictated by the application and are typically in the range of 100 to 500ms, for example ~200ms for telephony4 and ~330ms for interventional guidance5. In this work, we evaluate the latency and image quality of Nyquist and sub-Nyquist sampling using zero-filled reconstruction and unconstrained parallel imaging.Methods
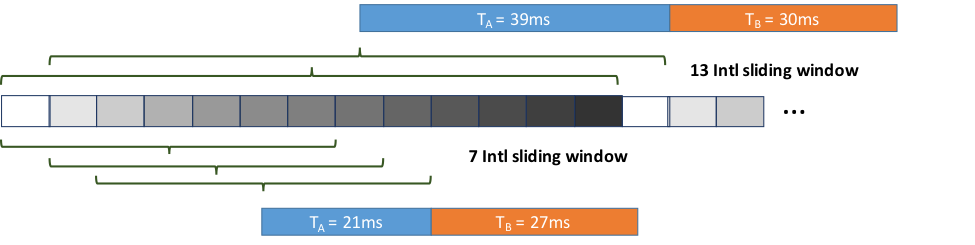
Speech RT-MRI data was collected as described by Lingala et al.6, using a GE Signa Excite 1.5T scanner with a custom eight channel upper airway coil. Acquisition parameters: golden angle spiral GRE; 2.4x2.4 mm2 spatial resolution; 2.52ms readout time; 6ms repetition time; 15° flip angle; 6 mm slice thickness; sliding window reconstruction with a shift of 1 interleaf. Images were reconstructed with 13, 11, 9, 7, 5, & 3 spiral interleaves/frames, using multi-coil Non-Uniform Fast Fourier Transform (NUFFT)7 as the initial estimate. Images were optionally refined using conjugate gradient (CG) SENSE8 with 1 or 2 iterations. NUFFT for sub sampled data is equivalent to density compensated zero-filled reconstruction. All reconstruction was implemented on 2.7GHz Intel Core i5 processor. We measure and report two components of latency--acquisition latency (TA) and reconstruction latency (TB)—as illustrated in Figure1.
Analysis was performed using
data from one healthy volunteer performing beat boxing at a rapid pace.
Off-line temporal finite-difference constrained reconstruction6 was performed and used as the
gold-standard for image quality. Articulation events were analyzed using the
intensity-vs-time profiles that include the tongue tip and lips to evaluate
spatiotemporal fidelity. Images were visually inspected by three experienced
users of speech RT-MRI (with a combined 15 years of experience).
Results & Discussion
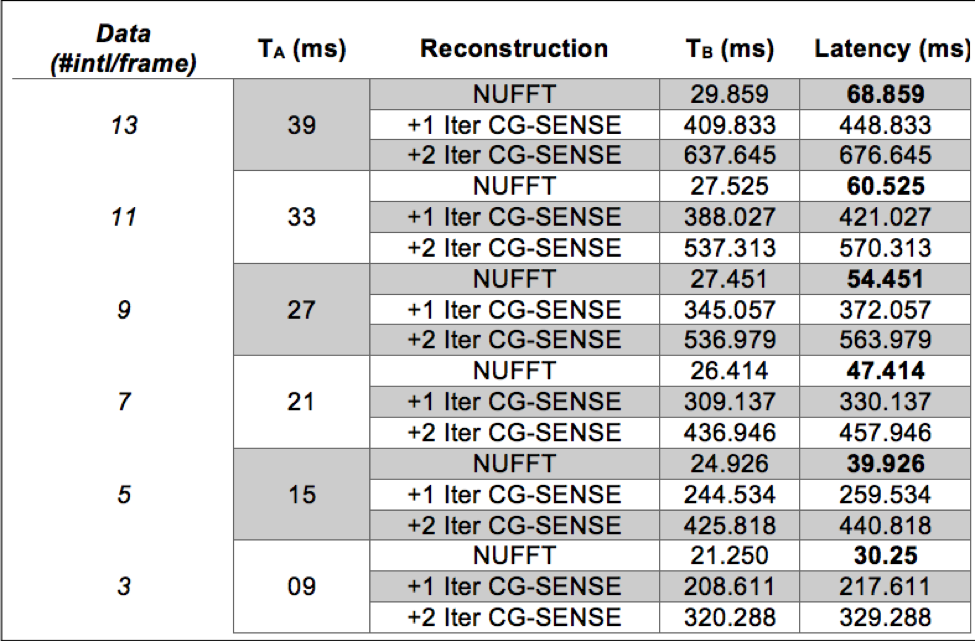
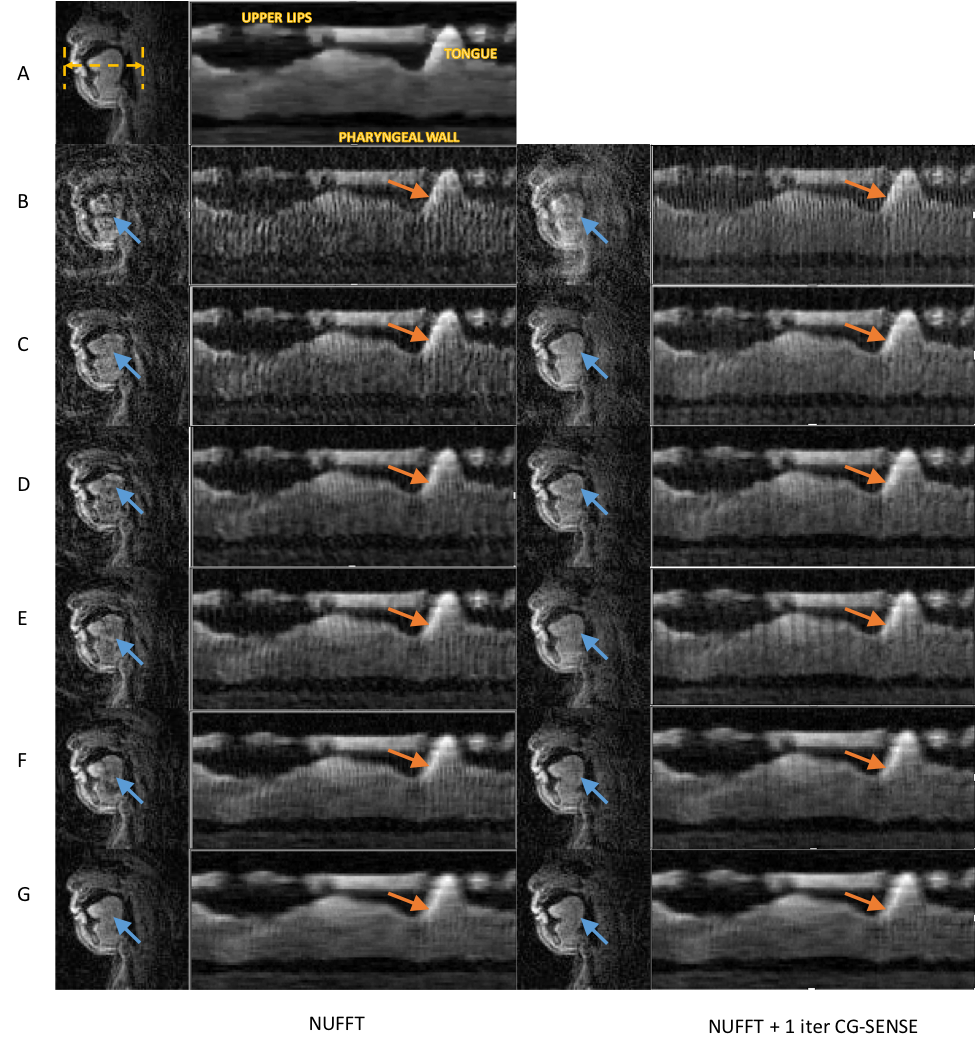
Table 1 lists the acquisition latency (TA) and reconstruction latency (TB) for each setting. NUFFT provides exceptionally low latency <70ms. There was a decrease in latency for lower numbers of interleaves/frame. Figure 2 illustrates the image quality for each tested reconstruction setting. As expected, sub-Nyquist sampling (<13 interleaves per frame) results in noise-like aliasing artifacts from the undersampled spiral acquisition (blue arrows), but also provides finer temporal resolution (red arrows). Overall latency of all options considered was substantially lower than Temporal FD constrained reconstruction which provides the best image quality but with a latency of 4.529 sec. The readers’ assessment was that >7-interleaves with NUFFT (zero-filled reconstruction) was sufficient to confirm stimuli compliance, and identify subject motion. This can be provided with latency of 68.86ms. The reconstruction method of choice may change if more nuanced information is needed interactively by the operator. As speech MRI needs and analysis techniques evolve9, some of these may also be desired in real-time. Two applications we envision are guided closed-loop feedback for first language speech therapy and second language learning.Conclusion
We demonstrate low-latency reconstruction for speech RT-MRI, which is compatible with existing state-of-the-art sampling, and provides the requisite real-time feedback to the scan operator. Specifically, we were able to provide latency less than 70ms by using sub-Nyquist sliding window reconstruction and were able to see tip of the tongue movement with negligible temporal blurring even during fast beat-boxing.Acknowledgements
We acknowledge grant support National Institute of Health (R01DC007124), National Science Foundation (1514544) and a USC Annenberg Graduate Fellowship (to S.S.). We thank Speech Production and Articulation kNowledge (SPAN) group at the University of Southern California, Los Angeles, CA, USA.References
1. Lingala SG, Sutton BP, Miquel ME, Nayak KS. Recommendations for real‐time speech MRI. J Magn Reson Imaging, 2016;43:28–44.
2. Scott AD, Wylezinska M, Birch MJ, Miquel ME. Speech MRI: morphology and function. Phys Med, 2014;30:604–618.
3. Dietz B, Fallone BG, Wachowicz K. Nomenclature for real‐time magnetic resonance imaging. Magn Reson Med. 2018;00:1–2. https://doi.org/10.1002/mrm.27487
4. Munhall KG, Gribble P, Sacco L, Ward M. Temporal constraints on the McGurk effect. Percept Psychophys. (1996);58:351–362.
5. Nguan C, Miller B, Patel R, Luke PP, Schlachta CM. Pre-clinical remote telesurgery trial of a da Vinci telesurgery prototype. Int J Med Robotics Comput Assist Surg. 2008;4:304–309.
6. Lingala SG, Zhu Y, Kim YC, Toutios A, Narayanan S, Nayak KS. A Fast and Flexible MRI System for the Study of Dynamic Vocal Tract Shaping. Magn Reson Med. 2017;77:112–125.
7. Fessler JA, Sutton BP. Nonuniform fast Fourier transforms using min-max interpolation. IEEE Trans Signal Process. 2003;51:560–574.
8. Pruessmann KP, Weiger M, Börnert P, Boesiger P. Advances in sensitivity encoding with arbitrary k‐space trajectories. Magn Reson Med. 2001;46:638–651.
9. Ramanarayanan V, Tilsen S, Proctor M, Töger J, Goldstein L, Nayak KS, Narayanan S. Analysis of speech production real-time MRI. Comput Speech Lang. 2018;52:1-22
Figures